
7x24小时咨询热线
400-660-3310
当前位置 : 好学校 上海大数据 优极限学堂 课程正文
优极限学堂
认证等级
优极限学堂
已获好学校V2信誉等级认证
信誉值
与好学校签订读书保障协议:
课程详情
开班信息
校区地址
学校相册
读书保障
手机预订再优惠![]()

微信关注好学校
报读课程额外再返现
课程优势亮点
课程技术体系全覆盖
本套课程包含了EB级架构设计架构底层技术体系、EB级架构设计数据分布式采集体系、数据中间件技术体系、数据存储技术体系、数据处理技术体系、OLAP生态体系、稳健架构设计体系、集群调度管理体系、数据挖掘体系、项目架构设计体系课程,包含了大数据技术体系全部内容。
大数据岗位全覆盖
本套课程设计覆盖互联网大厂全部岗位,涵盖从技术小白到大数据架构全部技术、课程包含大数据各类数据采集、数据缓存、数据存储、数仓构建、数据处理、数据挖掘、数据可视化、技术对比选型、平台开发、技术组件的二开、质量监控平台开发、源码深度解读等技术方面,技术覆盖大数据全部岗位。
对标互联网架构师课程设计
本套课程中不仅面向零基础小白,同时也适合工作多年的大数据开发人员技术提升,课程内容既有深度又有广度,针对每个技术点都有完整的理论知识体系及生产场景实战案例分析,技术原理源码级讲解,企业级项目架构设计方式及代码级讲解,基于互联网大厂案例驱动教学,在通向大数据架构师的道路上助你一臂之力。
一对一技术路线规划
根据每位学员在工作学习中掌握的技能点不同、公司内部使用的技术不同、学习提升目的不同,我们针对不同技术层次的同学设置一对一的技术路线规划,只为找到针对个人最适合、高效、最特色的学习步骤,通过一对一技术路线规划学习路径,来达到升职涨薪的最终目的。
一对一问题答疑
在学习过程中同学难免遇到各种问题,在学习中遇到的各种问题都可以直接找到授课老师进行一对一问题答疑,对症下药,直到解决问题为止。此外,在工作中遇到的各种技术问题,也可以直接找到对应的老师来进行技术指导,可谓“一次学习,售后终生”,解决同学学习到职场中遇到的各种问题。
贴心助教陪伴学习
如果你担心自己不能持之以恒学习,不用担心,我们安排了班主任贴心督学、指导,并且还有vip学员答疑群,资深老师群内专业解答,班级同学互相讨论,学习不再是孤军奋战!
大数据课程标准
为什么要培训成为高级数据开发工程师?
01.全链路数据开发培训课程
02.以“周”为单位更新课程/前沿技术
03.至少包含3个企业级数据开发大型项目
04.项目课程占比超过40%
05.数据开发技术课程深入且广泛
06.培养数据开发思维
07.多行业项目实战助力高薪就业
大数据课程大纲
| 阶段 | 周次 | 主要学习方向 |
| 第1阶段Linux和高并发阶段 | 正式班第01周 | •计算机组成原理、Linux 系统安装使用 •Linux初级命令、Linux的文件系统 •Linux文本操作及权限操作、Linux的三剑客 •Linux文本分析、Linux的网络与时间 •Linux进程管理 •LVS-DNAT-DR-TUN 调度算法 •Linux安装管理(rpm,yum) •Linux的Shell编程 •Nginx原理与配置 •Nginx反向代理与负载均衡 •Zookeeper背景与介绍与环境及安装 •Zookeeper源语命令操作与元数据信息的意义 |
| 第2阶段Hadoop生态体系阶段 | 正式班第02周 | •算法资源与大数据思维 •Hadoop分布式文件系统架构 •HDFS数据安全与传输流程 •搭建高可用分布式集群 •HDFS3.x高可用与联邦机制 •HDFS3.x的新特性、Window访问HDFS •MapReduce体系结构 •MapReduce算法思想 •MapReduce源码剖析 •MapReduce案例:天气数据统计 |
| 正式班第03周 | •MapReduce案例:好友推荐系统 •MapReduce案例:PageRank •MapReduce案例:豆瓣电影250 •MapReduce案例:TF-IDF •数据仓库基础 •Hive架构与搭建 •Hive查询访问 •Hive DDL和数据分区分桶 •Hive DML •Hive执行原理与优化 |
|
| 第3阶段电商日志分析 | 正式班第04周 | •Hbase架构与数据存储模型 •Hbase表结构 •Hbase 读写数据流程与存储数据结构LSM树 •Hbase standalone模式安装 •Hbase 完全分布式安装与Hbase 高可用 •Hbase搭建注意与Hbase基本命令 •项目:电商日志维度分析基本介绍 •项目:电商日志业务分析 •项目:电商数据来源与日志收集 •项目:电商数据流程图 •项目:电商项目数据采集项目配置 •项目:电商项目MapReduce实现数据清洗 |
| 正式班第05周 | •项目:电商项目数据库表设计理念 •项目:电商项目活跃用户TopN开发和运行 •项目:项目总结 •项目:数据处理流程 •Flume简介和Flume安装 •Flume使用和知识拓展 •DataX概览和安装 •DataX使用和DataX-Web •Azkaban架构和部署 •Azkaban的集群搭建和实战 |
|
| 第4阶段企业常用中间件 | 正式班第06周 | •索引、分词器和ElasticSearch数据存储结构 •ElasticSearch基本命令和插件安装、JavaAPI •基于zookeeper 的分布式协调案例 •Kafka 分布式消息系统介绍 •Kafka 应用场景 •Kafka 生产消息原理 •Kafka Topic、partition 原理 •Kafka 集群搭建/Kafka 命令使用 •KafkaTopic更改、删除 •API操作Kafka •redis发展史与特点 •安装redis及使用命令行客户端 •redis 的常见数据类型 •如何使用java访问redis •redis 的事务(transaction) •redis优化 •redis的 sentinel高可用 •redis3.x集群安装配置 |
| 第5阶段Spark计算框架体系阶段 | 正式班第07周 | •scala语言六大特性 •Scala下载安装 •Scala环境配置 •IDEA 开发Scala 配置 •Scala 数据类型与类型推断机制 •Scala 类和对象/Scala 循环、判断 •Scala 基本语法 •Scala 函数及应用(匿名函数、高阶函数等) •Scala Array 操作 •Scala可变数组操作 •Scala 可变列表操作 •Scala 中Set、Map、元组操作及要点 •Scala 样例类 •Scala trait特征特质 •Scala伴生类 •Scala 伴生对象 •Scala 模式匹配 •Scala actor通信模型 •Spark 技术介绍/Spark 技术站详解 •Spark 演变历史/Spark 与MR的区别 •Spark 运行模式介绍 •Spark 集群搭建/Spark 配置选项详解 •Spark 原理简介 •Spark RDD弹性分布式数据集 •Spark map算子使用 •Spark flatMap算子使用 •Spark filter、sample算子使用 •Spark count、foreach算子使用 |
| 正式班第08周 | •持久化数据级别分类 •持久化算子cache使用 •Cache 要点注意事项 •持久化算子persist使用 •持久化算子Checkpoint •Checkpoint 执行流程 •Checkpoint 注意事项 •standalone集群的搭建 •standalone集群部署模式的任务提交操作 •spark on yarn部署(集群模式) •yarn模式下的客户端以及集群提交任务 •yarn模式下历史日志服务部署 •转换算子join union •转换算子mapPartitions distinct •触发算子foreachPartition •spark术语解析以及宽窄依赖 •stage概念 •宽窄依赖切割原理 •管道pipeline计算模式测试 •资源调度以及任务调度流程解析 •spark资源申请粒度 •推测执行机制 •转换算子mapPartitionsWithIndex repartition •coalesce与repartition区别详解 •groupByKey与reduceByKey算子区别详解countByKey与countByValue等算子解析 •spark应用程序常用工具类编写 •spark pv,uv案例、二次排序案例、分组取topN案例 •spark-submit任务提交命令参数详解 •sparkShell相关操作 •历史日志服务以及webUI操作解析 |
|
| 第6阶段Spark计算框架体系阶段 | 正式班第09周 | •spark的MasterHA配置 •共享变量之累加器以及广播变量 •sparkShuffle分类及差异解析 •sparkshuffle参数调优 •sparkshuffle的文件寻址 •spark的内存管理 •spark集群启动源码解析 •spark Master角色源码(通信处理,应用注册等) •spark初始化部分源码解析 •spark schedule源码解析 •spark core篇复习回顾 •spark sql篇展望 •sparkSql核心操作对象dataSet •sparkSql底层架构以及谓词下推等概念介绍 •idea构建项目sparkSql读取json格式数据 •idea构建项目sparkSql读取非json格式数据 •sparkSql动态创建schema信息 •sparkSql读取mysql和读取parquet •sparkSql读取Hive数据 •序列化问题 •udf以及udaf函数的编写 •开窗函数的使用 |
| 正式班第10周 | •sparkStreaming介绍 •sparkSteaming模型图解 •receiver模式存在的问题 •实时处理socket连接数据 •准实时处理微批处理的概念及注意点 •foreachRDD算子注意事项 •transform算子注意事项 •updateStateByKey算子注意事项 •window窗口操作及优化手段 •sparkStreaming和kafka0.8的receiver模式 •sparkStreaming和kafka0.8的direct模式 •sparkStreaming实际开发任务处理参数调优 •webUI以及反压机制的介绍 •kylin的背景介绍/kylin的应用场景 •kylin的部署方式/kylin安装部署 •KyLin和Hive/KyLin和hbase •kylin事实表/kylin维度表 |
|
| 正式班第11周 | •项目:车流量项目简介 •项目:车流量项目数据模拟 •项目:车流量卡口状态监控图 •项目:车流量项目自定义累加器 •项目:车流量项目行车轨迹 •项目:车流量项目卡口下的行车轨迹 •项目:车流量项目集群规模估算 •项目:车流量项目道路转化率 •项目:车流量项目实时拥堵业务 •项目:车流量项目的总结 |
|
| 第7阶段Flink实时计算系统阶段 | 正式班第12周 | •Flink简介 •Flink架构组成 •Flink 开发环境配置 •Flink 批次处理和流式处理案例 •虚拟key的操作方式 •daaSource的创建方式 •transformation 操作符介绍 •sink 操作符使用以及灵活使用addSink •Flink集群部署角色介绍 •Flink on Yarn部署方式(两种) •Flink并行度解析 •Flink窗口分类使用 •Flink时间类型以及水印 •waterMark整体介绍及定义方式 •Flink广播变量和累加器的使用 •Checkpoint的开启与设置 •状态后端存储 •savepoint的使用以及和checkpoint的区别 •操作链的使用方式 •taskSlots的原理 •historyserver日志服务的配置 •kafka连接器的使用与整合 |
| 第8阶段CDH+OIZE+HUE+IMPALA | 正式班第13周 | •cloudera manager框架原理 •纯手工安装cloudera manager •cloudera manager部署CDH •cloudera manager管理主机 •cloudera manager管理集群、管理服务 •cloudera manager管理实例、管理配置 •cloudera manager管理监控、管理资源 •cloudera manager service图表使用 •cloudera manager service图表创建 •cloudera manager service的 dashboard •Hue 介绍 •Hue 安装 •Hue 的HIVE管理与使用 •Hue 的Oozie 管理与使用 •Hue 的metadata管理与使用 •Hue 的用户管理与使用 •Impala介绍/内存计算与 MR,SPARK 计算的比较 •impala框架角色讲解/impala的安装 •impala的命令行使用/impala的命令参数详解 •Oozie 框架角色原理 •Oozie 的xml 配置文件 •Oozie 的job 配置文件 •numpy安装/numpy基础 •矩阵的创建/矩阵的属性 •矩阵的常用函数 •矩阵的迭代/矩阵的形状操作 |
| 第9阶段机器学习和算法体系阶段 | 正式班第14周 | •线性回归算法原理 •多元线性回归算法 •贝叶斯分类算法 •KNN分类算法 •Kmeans算法、Kmeans++算法 •TF-IDF算法 •逻辑回归分类算法 •决策树算法 •随机森林算法 •推荐系统原理 |
| 正式班第15周 | •项目:推荐系统解决的问题和价值 •项目:推荐系统的架构和场景分析 •项目:推荐系统的埋点和离线召回 •项目:协同过滤和推荐系统的在线召回 •项目:推荐系统数据准备和离线任务(一) •项目:推荐系统数据准备和离线任务(二) •项目:推荐系统机器学习算法GBDT+LR •项目:推荐系统机器学习算法XGBOOST和pmml部署 •项目:推荐系统算法之神经网络 •项目:推荐系统深度学习算法之wide&deep |
|
| 正式班第16周 | •项目:推荐系统ab框架和评估 •项目:推荐项目日志收集和指标分析 •项目:游戏数据分析项目介绍 •项目:游戏数据分析数据结构和数据生成 •项目:数仓建模理论和数据ETL •项目:游戏数据渠道指标分析 •项目:游戏数据分析用户活跃留存指标分析 •项目:游戏数据用户付费指标分析 •简历项目撰写方法介绍 •简历项目撰写样例分析 |
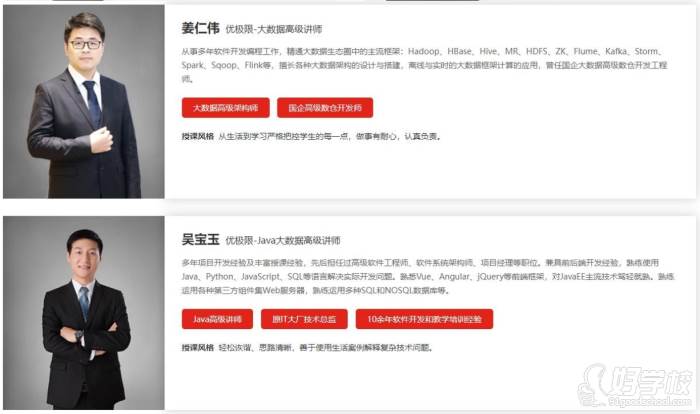
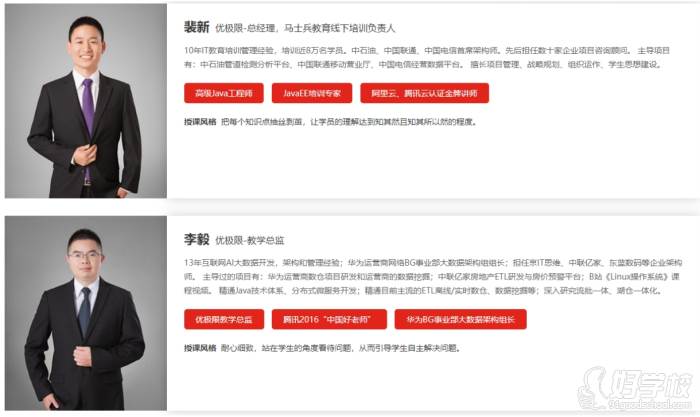
【老师介绍】





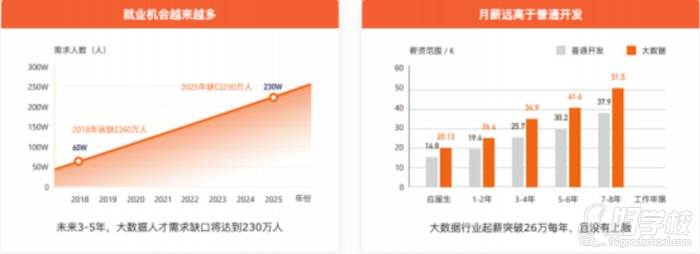
【大数据就业岗位和前景】
大数据研发:

大数据分析:
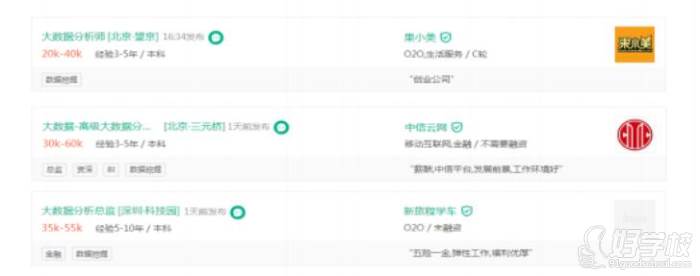
大数据运维:
【学员风采】



【教学现场】




校区地址
学校相册
更多 >



看过的人还关注了
更多适合课程
全城大数据学校,一网打尽,立即搜索:
在线预约免费试听
 官方授权声明
官方授权声明
尊敬的平台会员您好,[优极限学堂]资质文件正在审核中。如需了解[优极限学堂]服务明细或申请试听服务,
请点击:联系客服。




.png)
.png)
.png)
.png)






 粤公网安备 44010602004272号
粤公网安备 44010602004272号